如何优化MySQL的联表查询性能?
前言
为什么要研究联表查询的性能?在执行大型表的联表查询时,若两个大表进行关联,可能会导致查询时间过长。为了减少在生产环境中出现慢SQL查询,深入了解联表查询的机制及其优化方法变得较为重要。 在5.7中连接主要有:
- 嵌套循环连接(Nested-Loop Join):这是最基本的连接类型,对于每个在外表(左表)的行,MySQL扫描内表(右表)来寻找匹配的行。
- 索引嵌套循环连接(Indexed Nested-Loop Join):这种连接方式利用内表的索引来提高查询效率,对于外表的每一行,通过索引来查找内表中匹配的行。
- 块嵌套循环连接(Block Nested-Loop Join):这种方法通过减少对内表的访问次数来优化嵌套循环连接,它会将外表的一部分或全部加载到内存中,然后批量地处理这些数据。
- BKA连接(Batched Key Access Join):BKA连接是对块嵌套循环连接的改进,它利用索引来减少对内表的访问。这种方法会批量地从外表收集键值,然后使用这些键值通过索引来访问内表。
连接的分类
嵌套循环连接(nested-loop join)
嵌套循环连接(NLJ )实际上就相当于两层 for 循环,外层是 驱动表,内层是 被驱动表。也就是依次从驱动表中取出符合条件的行,然后用该行数据去执行内层for循环,即依次去匹配被驱动表的每一行。
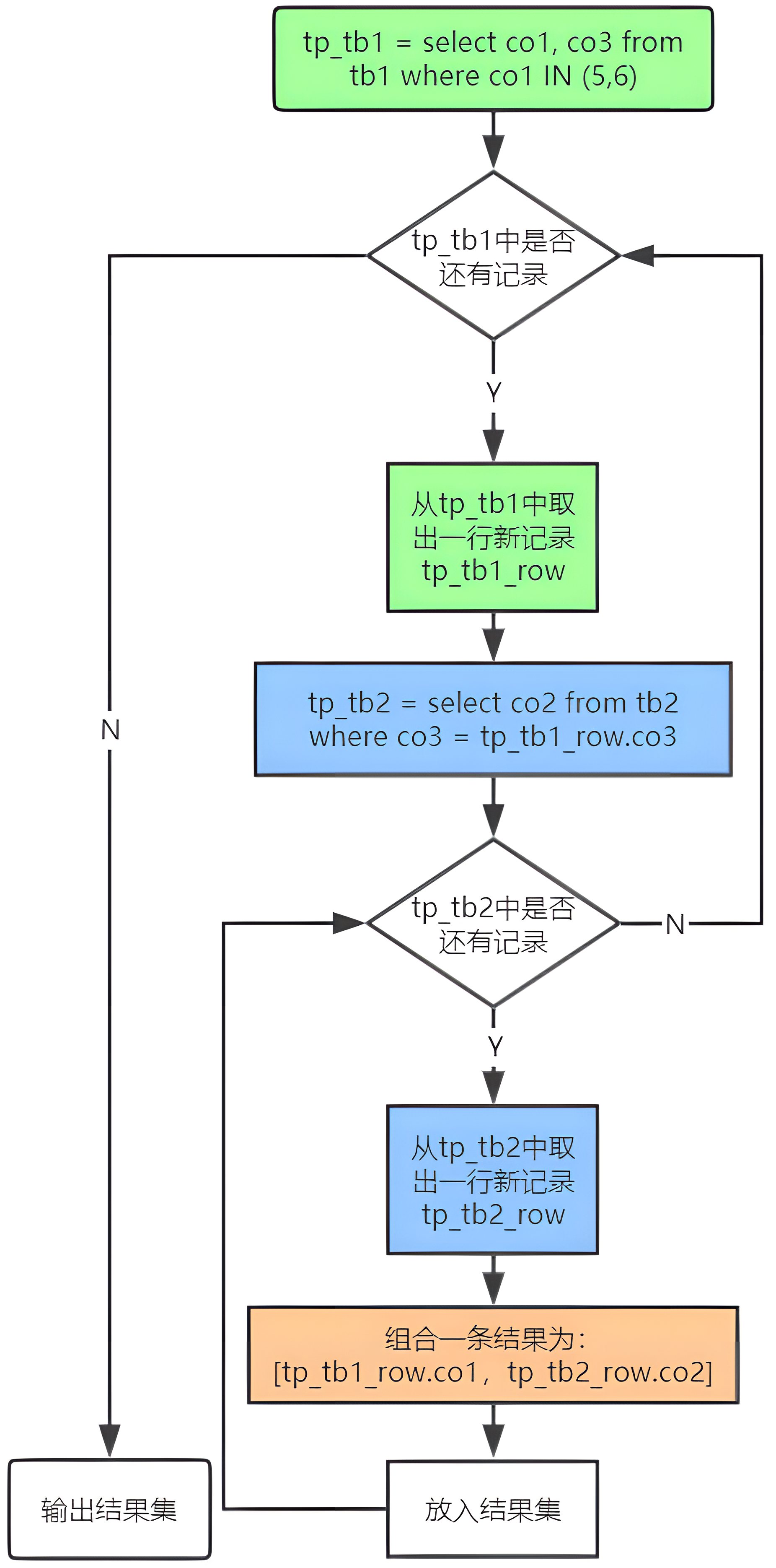
内连接示例
1
2
3
4
5
6
7
8
SELECT
tb1.co1,
tb2.co2
FROM
tb1
INNER JOIN tb2 ON tb1.co3=tb2.co3
WHERE
tb1.co1 IN(5, 6)
示例流程图如下:
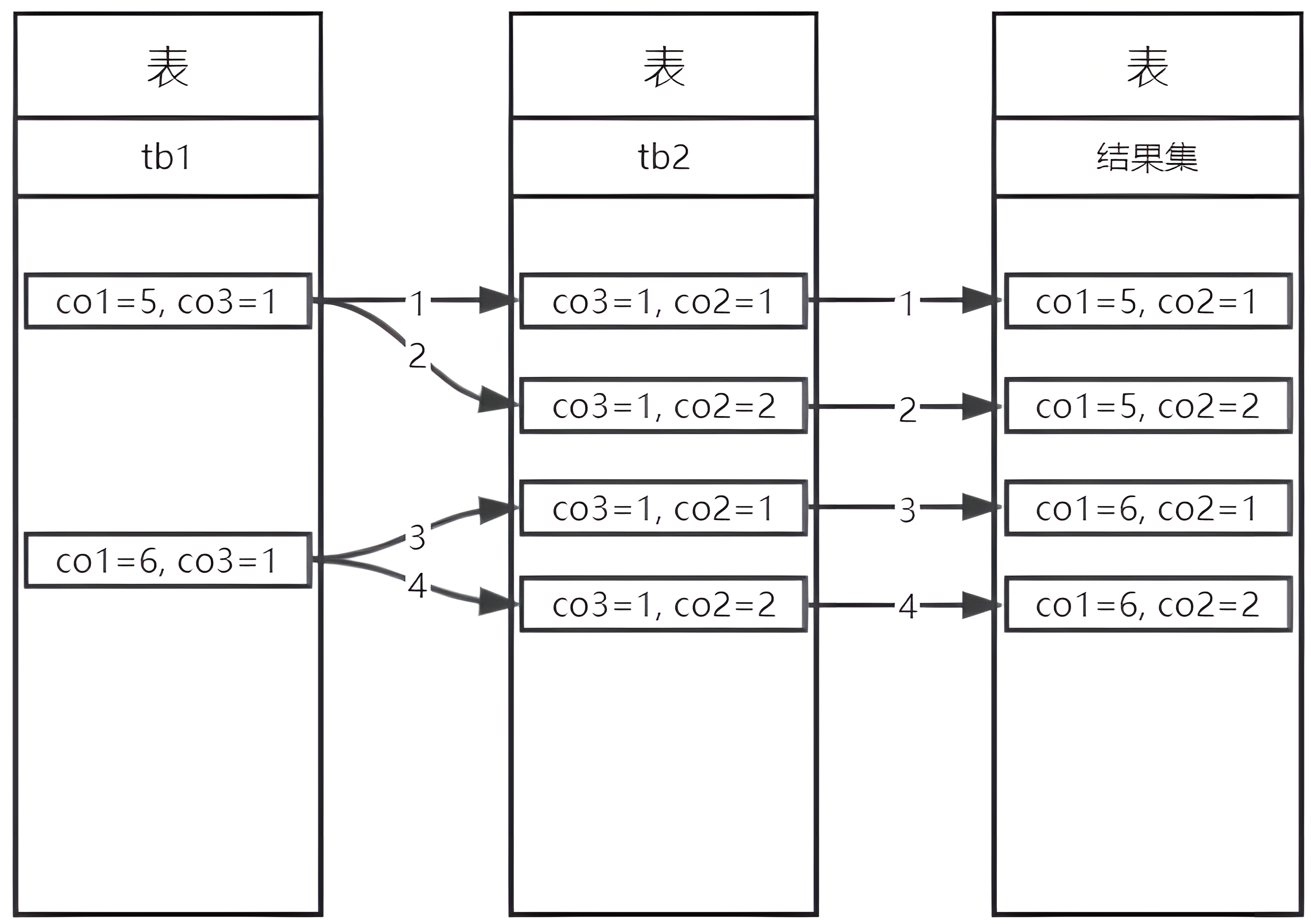
泳道图示意如下:
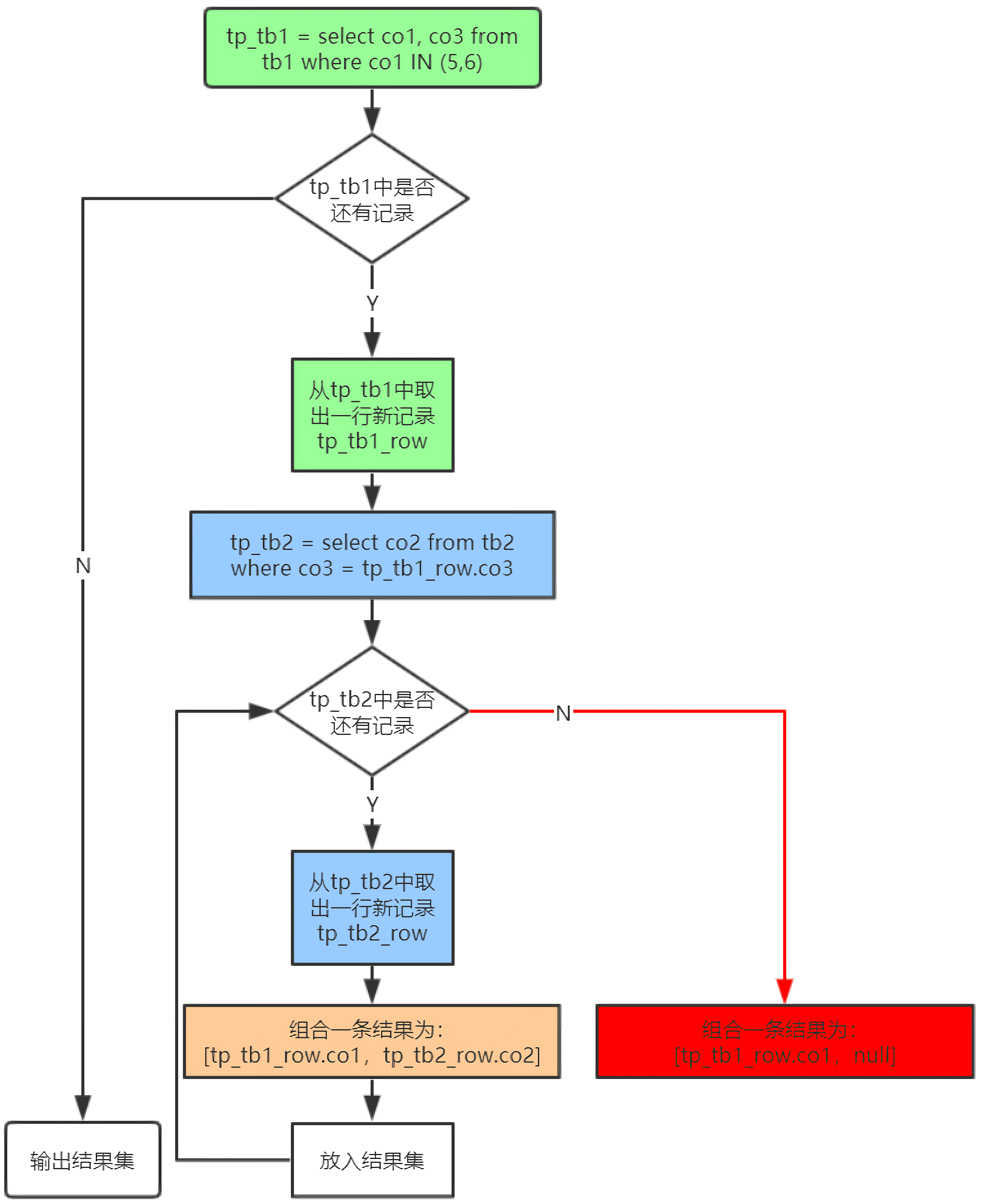
外连接示例
1
2
3
4
5
6
7
8
SELECT
tb1.co1,
tb2.co2
FROM
tb1
LEFT JOIN tb2 ON tb1.co3=tb2.co3
WHERE
tb1.co1 IN(5, 6)
示例流程图如下:
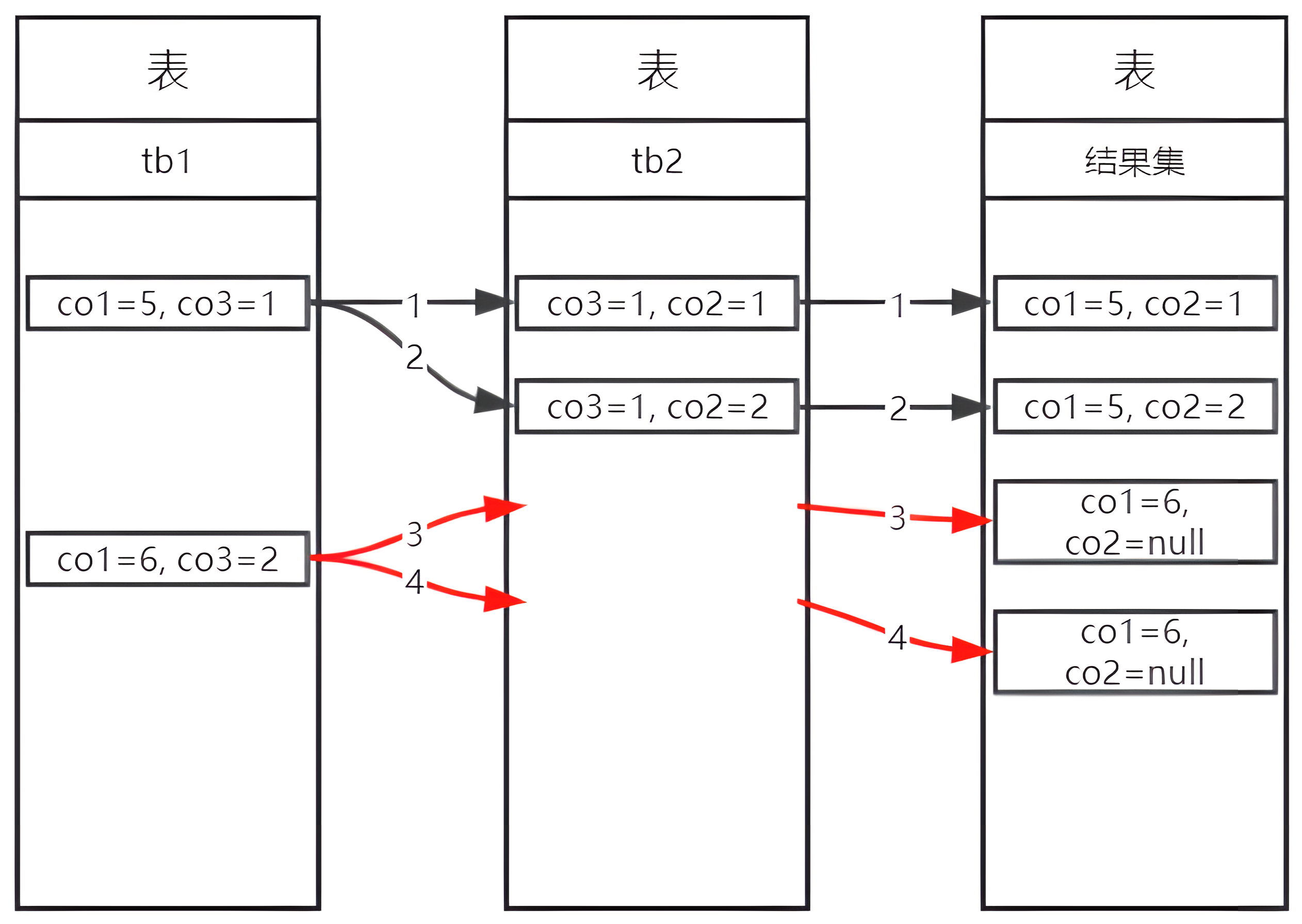
泳道图示意如下:
小结
无论采用何种类型的连接,如果tb1有100行数据满足条件,而tb2有1000行数据,那么就需要对tb2进行100次全表扫描,总共读取tb2表的10万行数据。
将每次数据行读取视为一次磁盘I/O操作的话,这将导致高达10万次的磁盘I/O,这一数字令人担忧。尽管可以通过各种缓存机制或顺序读取等手段来提高速度并减少I/O操作,但总体上性能仍然较低。
索引嵌套循环连接(Indexed Nested-Loop Join)
通过对 SELECT tb1.col1, tb2.col2 FROM tb1 INNER JOIN tb2 ON tb1.col3 = tb2.col3 WHERE tb1.col1 IN(5,6) 查询进行优化,我们考虑为tb2的 col3 添加索引。
添加索引后,内部循环不再需要进行全表扫描,而是可以利用索引直接定位到具体的数据行。这里假设tb2的 col3 是一个唯一索引,虽然整个查询流程没有变化,但是tb2的查询操作现在是通过索引进行的,这与之前没有索引的 INNER JOIN 操作相比,过程相同但效率大大提高。
因此,如果tb1有100行数据满足条件,而tb2有1000行数据,那么现在只需要对tb2执行100次索引查找。如果假设每次索引查找只涉及到一行数据,那么总共只需要读取tb2表的100行数据。这样的优化显著提升了性能。
块嵌套循环连接(Block Nested-Loop Join)
从MySQL 5.6版本开始,引入了块嵌套循环连接(Block Nested-Loop Join, BNL)技术,用以优化没有索引的情况。这种技术通过替换传统的嵌套循环连接算法,关键在于使用了 join buffer 这一内存缓存块。
具体来说,该算法通过将一张表的结果集存储到 join buffer 中,然后遍历另一张表的记录,逐行与 join buffer 中的数据进行匹配。例如,在连接表 t1 和 t2 时,可以先将 t1 的结果集读入 join buffer,随后扫描 t2 表,将 t2 中的每一行与 join buffer 中的数据行进行逐一匹配,最后输出最终的结果集。
尽管总体的遍历次数保持不变,但由于绝大多数遍历操作都在 join buffer 这个缓冲区内进行,因此整体速度得到了显著提升。
join连接注意事项
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SELECT
IF(p.name = i.name, '相等', '不一致') AS result,
i.id,
p.idcard,
p.o_c
FROM
g_p p
LEFT JOIN g_b_i i
ON p.idcard=i.card_no
WHERE
p.idcard='xxxxxxxxxxxxxxxxx'
AND p.o_c=xxxxxxx
LIMIT
1;
p表拥有超过2000万条数据,而i表则有超过800万条数据。尽管在p的idcard、p的o_c以及i的card_no上都建立了索引,理论上使用索引嵌套循环连接p.idcard和i.card_no应该能够利用到这些索引。然而,可能由于MySQL优化器的特定行为,实际上并没有采用索引进行查询。在数据库中测试发现耗时112224ms ,通过使用EXPLAIN命令进行分析,

我们发现查询实际上执行了全表扫描,而没有利用索引。
因此怀疑是不是因为IF(p.name = i.name, '相等', '不一致') AS result,这一句造成的。 于是我们删除这句sql语句为
1
2
3
4
5
6
7
8
9
10
11
12
13
SELECT
i.id,
p.idcard,
p.o_c
FROM
g_p p
LEFT JOIN g_b_i i
ON p.idcard=i.card_no
WHERE
p.idcard='xxxxxxxxxxxxxxxxx'
AND p.o_c=xxxxxxx
LIMIT
1;
再次执行,耗时8734ms ,耗时确实有所减少,但是理论上,那一句是不会对索引造成影响的。使用EXPLAIN发现type变为了index,但不是ref。
接着我们再次修改sql语句,在where中加入AND i.card_no = 'xxxxxxxxxxxxxxxxx' ,sql代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SELECT
i.id,
p.idcard,
p.o_c
FROM
g_p p
LEFT JOIN g_b_i i
ON p.idcard=i.card_no
WHERE
p.idcard='xxxxxxxxxxxxxxxxx'
AND p.o_c=xxxxxxx
AND i.card_no = 'xxxxxxxxxxxxxxxxx
LIMIT
1;
发现耗时只要20ms,EXPLAIN的type为ref,加上IF(p.name = i.name, '相等', '不一致') AS result依旧是相同结果
接着使用子查询的方式修改语句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
SELECT
IF(p.name = i.name, '相等', '不一致') AS result,
i.id,
p.idcard,
p.o_c
FROM
(
SELECT *
FROM g_p
WHERE idcard = 'xxxxxxxxxxxxxxxxx'
AND o_c = xxxxxxx
) p
LEFT JOIN
(
SELECT *
FROM g_b_i
WHERE card_no = 'xxxxxxxxxxxxxxxxx'
) i
ON p.idcard = i.card_no
LIMIT 1;
发现耗时18ms,EXPLAIN的type为ref,结果与前一次方式相同。
总结
在查询中通过WHERE子句添加筛选条件,以及先通过子查询筛选出较小的数据集进行连接,可能是一种更有效的优化策略。如果WHERE子句缺少必要的筛选条件,可能因为优化器的行为,导致执行全表扫描。